Scaling Pulp¶
Great effort has been put into Pulp to make it scalable. A default Pulp install is an “all-in-one” style setup with everything running on one machine. However, Pulp supports a clustered deployment across multiple machines and/or containers to increase availability and performance.
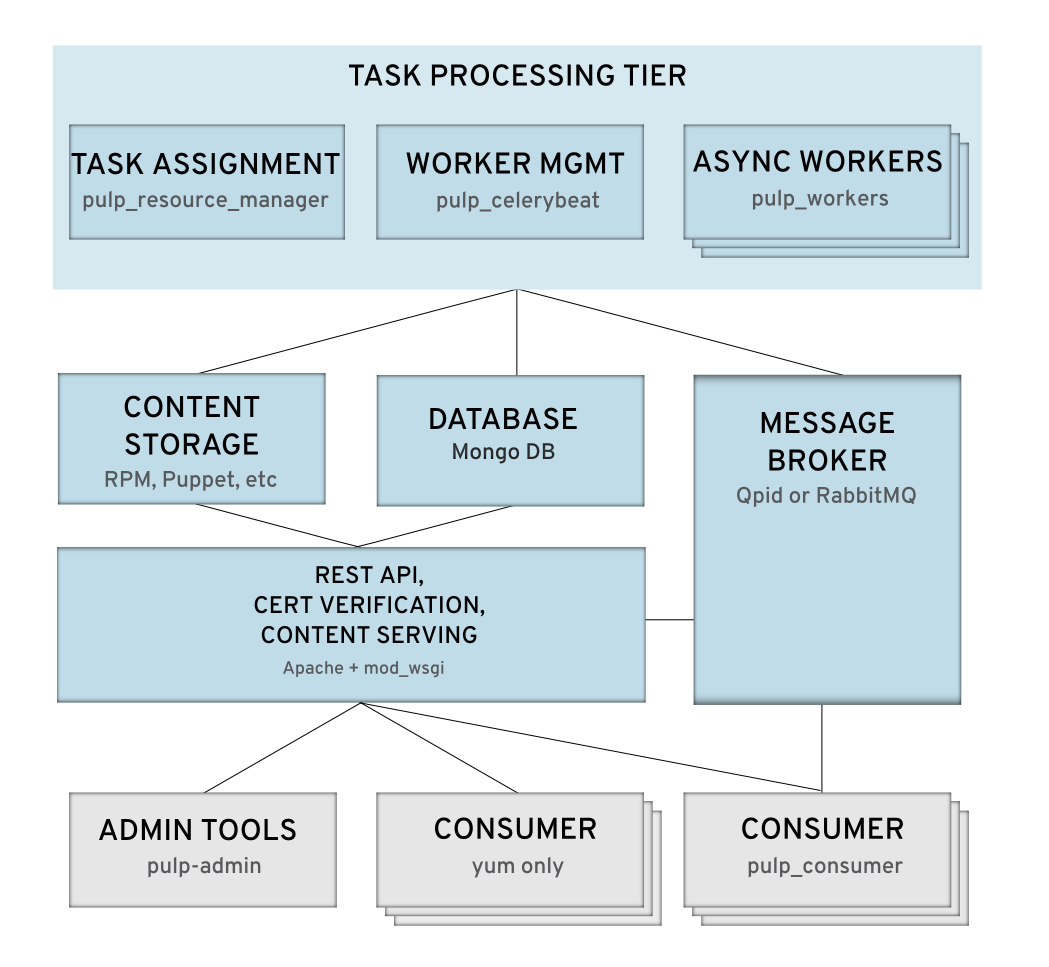
Overview of Pulp Components¶
Pulp consists of several components:
httpd- The webserver process serves published repositories and handles Pulp REST API requests. Simple requests like repository creation are handled immediately whereas longer tasks are asynchronously processed by a worker.pulp_workers- Worker processes handle longer running tasks asynchronously, like repository publishes and syncs.pulp_celerybeat- The celerybeat process discovers and monitors workers. Additionally, it performs task cancellations in the event of a worker shutdown or failure. The celerybeat process also initiates scheduled tasks, and automatically cancels tasks that have failed more than X times. This process also initiates periodic jobs that Pulp runs internally. Multiple instances of thepulp_celerybeatprocess can run at the same time to ensure high availability of the Pulp.pulp_resource_manager- The resource manager assigns tasks to workers, and ensures multiple conflicting tasks on a repo are not executed at the same time. Multiple instances ofpulp_resource_managercan be running at a time, but if the activepulp_resource_managerinstance becomes unavailable, there will be a delay before another can take over, potentially causing a gap in service.
Additionally, Pulp relies on other components:
- MongoDB - the database for Pulp
- Apache Qpid or RabbitMQ - the queuing system that Pulp uses to assign work to workers. Pulp can operate equally well with either Qpid or RabbitMQ.
The diagram below shows an example default deployment.
Choosing What to Scale¶
Not all Pulp installations are used in the same way. One installation may have hundreds of thousands of RPMs, another may have a smaller number of RPMs but with lots of consumers pulling content to their systems. Others may sync frequently from a number of upstream sources.
A good first step is to figure out how many systems will be pulling content from your Pulp installation at any given time. This includes RPMs, Puppet modules, Docker layers, OSTree layers, Python packages, etc. RPMs are usually pulled down on a regular basis as part of a system update schedule, but other types of content may be fetched in a more ad-hoc fashion.
If the number of concurrent downloads seems large, you may want to consider adding additional servers to service httpd requests. See the Scaling httpd section for more information.
If you expect to maintain a large set of repositories that get synced frequently, you may want to add additional servers for worker processes. Worker processes handle long-running tasks such as content downloads from external sources and also perform actions like repository metadata regeneration on publish. See the Scaling workers section for more information.
Another consideration for installations with a large number of repositories or repositories with a large numbers of RPMs is to have a dedicated server or set of servers for MongoDB. Pulp does not store actual content in the MongoDB database, but all metadata is stored there. More information on scaling MongoDB is available in the MongoDB Deployment docs.
Pulp uses either RabbitMQ or Apache Qpid as its messaging backend. Pulp does not generate many messages in comparison to other applications, so it is not expected that the messaging backend would need to be scaled for performance unless the number of concurrent consumer connections is large. However, additional configuration may be done to make the messaging backend more fault tolerant. Examples of this are available in the Apache Qpid HA docs and the RabbitMQ HA docs.
Warning
There is a bug in versions of Apache Qpid older than 0.30 that involves running out of file descriptors. This is an issue on deployments with large numbers of consumers. See RHBZ #1122987 for more information about this and for suggested workarounds.
Scaling httpd¶
Additional httpd servers can be added to Pulp to increase both throughput and redundancy.
In situations when there are more incoming HTTP or HTTPS requests than a single server can respond to, it may be time to add additional httpd servers. httpd serves both the Pulp API and content, so increasing capacity could improve both API and content delivery performance.
Consider using the Apache mod_status scoreboard to monitor how busy your httpd workers are.
Note
Pulp itself does not provide httpd load balancing capabilities. See the Load Balancing Requirements for more information.
To add additional httpd server capacity, configure the desired number of
Pulp clustered servers and start httpd on them.
Scaling workers¶
Additional Pulp workers can be added to increase asynchronous work throughput and redundancy.
To add additional Pulp worker capacity, configure the desired number of Pulp
clustered servers according to the the clustering docs and start
pulp_workers on each of them. Remember only one instance of pulp_resource_manager
should be running across all Pulp clustered servers.
Clustering Pulp¶
A clustered Pulp installation is comprised of two or more Pulp clustered servers. The term Pulp clustered server is used to distinguish it as a separate concept from Nodes. Pulp clustered servers share the following components:
| Pulp Configuration | Pulp reads its configuration from conf files inside
/etc/pulp. |
| Pulp Files | Pulp stores files on disk within /var/lib/pulp. |
| Certificates | By default, Pulp keeps certificates in
/etc/pki/pulp. |
| MongoDB | All clustered Pulp servers must connect to the same MongoDB. |
| AMQP Bus | All consumers and servers must connect to the same AMQP bus. |
Filesystem Requirements¶
Pulp requires a shared filesystem for Pulp clustered servers to run correctly. Sharing with NFS has been tested, but any shared filesystem will do. Pulp expects all shared filesystem directories to be mounted in their usual locations.
The following permissions are required for a Pulp clustered server to operate correctly.
| User | Directory | Permission |
|---|---|---|
| apache | /etc/pulp |
Read |
| apache | /var/lib/pulp |
Read, Write |
| apache | /etc/pki/pulp |
Read, Write |
| root | /etc/pki/pulp |
Read |
For more details on using NFS for sharing the filesystem with Pulp, see Sharing with NFS.
SELinux Requirements¶
Pulp clustered servers with SELinux in Enforcing mode need the following SELinux file contexts for correct operation:
| Directory | SELinux Context |
|---|---|
/etc/pulp |
system_u:object_r:httpd_sys_rw_content_t:s0 |
/var/lib/pulp |
system_u:object_r:httpd_sys_rw_content_t:s0 |
/etc/pki/pulp |
system_u:object_r:pulp_cert_t:s0 |
For more details on using NFS with SELinux and Pulp, see Sharing with NFS.
Server Settings¶
Several Pulp settings default to localhost, which won’t work in a
clustered environment. In /etc/pulp/server.conf the following settings
should be set, at a minimum, for correct Pulp clustering operation.
| Section | Setting Name | Recommended Value |
|---|---|---|
| [server] | host | Update with the name used by your load balancer. |
| [database] | seeds | Update with the hostname and port of your network accessible MongoDB installation. |
| [messaging] | url | Update with the hostname and port of your network accessible AMQP bus installation. |
| [tasks] | broker_url | Update with the hostname and port of your network accessible AMQP bus installation. |
MongoDB Automatic Retry¶
Pulp can be configured to automatically retry calls to the database if there is a connection error
between the server and the database. The setting, unsafe_autoretry is located in the
[database] section of /etc/pupl/server.conf.
Warning
This feature can result in duplicate records, use with caution.
Load Balancing Requirements¶
To effectively handle inbound HTTP/HTTPS requests to Pulp clustered
servers running httpd, load balancing of some sort should be
used. Pulp clustered servers not running httpd do not need to be
involved in load balancing. Configuring load balancing is beyond the
scope of Pulp documentation, but there are a few recommendations.
One option is to use a dedicated load balancer. Pulp defaults to using SSL for webserver traffic, so an easy thing is to use a TCP based load balancer. HAProxy has been tested with a clustered Pulp installation, but any TCP load balancer should work.
Another option is to use DNS based load balancing. Community users have reported this works, but it has not been explicitly tested by Pulp developers.
With either load balancing technique, all Pulp clustered servers
running httpd need to be configured with SSL certificates which
have the CN set to the hostname of the TCP load balancer or the DNS
record providing load balancing. This ensures that as traffic arrives
at Pulp webservers, clients will trust the certificate presented by
the Pulp clustered server.
Clustered Logging¶
Pulp logs in the same way on a clustered server as it does for a single server. For more information on how Pulp logs, see Logging. To setup remote logging and aggregation, refer to the documentation for the log daemon running on your system.
Cluster Monitoring¶
A clustered deployment can be monitored with the techniques described in Getting the Server Status.
Warning
Information provided by the /status/ API call does not
include httpd status information. It is recommended that each
Pulp clustered server acting as a webserver have its /status/
API queried directly. If queried through the load balancer, the
request may route to httpd servers in unexpected ways. See
issue #915 for more information.
Consumer Settings¶
Consumers use a similar configuration as they would in a non-clustered
environment. At a minimum there are two areas of
/etc/pulp/consumer/consumer.conf which need updating.
- The
hostvalue in the[server]needs to be updated with the load balancer’s hostname. This causes web requests from consumers to flow through the load balancer. - The
[messaging]section needs to be updated to use the same AMQP bus as the server.
Warning
Machines acting as a Pulp clustered nodes cannot be registered as a consumer until #859 is resolved.
Pulp Admin Settings¶
When using a clustered deployment, it is recommended to configure
pulp-admin to connect to the load balancer hostname. To do this, add
the following snippet to ~/.pulp/admin.conf
[server]
host: example.com
# This example assumes example.com is your load balancer or DNS record
# providing load balancing
Sharing with NFS¶
NFS has been tested with Pulp to share the /etc/pulp, /var/lib/pulp,
and /etc/pki/pulp sections of the filesystem, but any shared filesystem
should work. Typically Pulp clustered servers will act as NFS clients,
and a third party machine will act as the NFS server.
Warning
Exporting the same directory name (ie: pulp) multiple times can cause the
NFS client to incorrectly believe it has already mounted the export. Use
the NFS option fsid with integer numbers to uniquely identify NFS
exports.
NFS expects user ids (UID) and group ids (GID) of a client to map directly
with the UID and GID on the server. To keep your NFS export config simple,
it is recommended that all NFS servers and clients have the same UID and GID
for the user apache. If they differ throughout the cluster, use NFS
options to map UIDs and GIDs accordingly.
Most NFS versions by default squash root which prevents root on NFS
clients from automatically having root access on the NFS server. This
typically prevents root on a Pulp clustered server from having the
necessary Read access on /etc/pki/pulp. One secure way to workaround
this without opening up root access on the NFS server is to use the
anonuid and anongid NFS options to specify the UID and GID of
apache on the NFS server. This will effectively provide root on the
NFS client with read access to the necessary files in /etc/pki/pulp.
If using SELinux in Enforcing mode, specify the necessary
SELinux Requirements with the NFS option context.