Alternate Download Policies¶
Pulp supports several methods for downloading the content units in a repositories. These methods are referred to as download policies. By default, Pulp uses the immediate download policy to download content. To use an alternate download policy, several services need to be installed and configured. The advantage of using an alternate download policy is that it allows Pulp to serve clients or copy content between repositories without downloading every content unit first. When a repository is created, its download policy can be set.
Note
Not all content types have repository metadata, which is required when using any of the deferred download policies. Therefore, some content types are limited to the default immediate download policy.
Overview of Deferred Downloading Components¶
The diagram below provides a high-level overview of how the deferred download services interact with the Pulp core services.
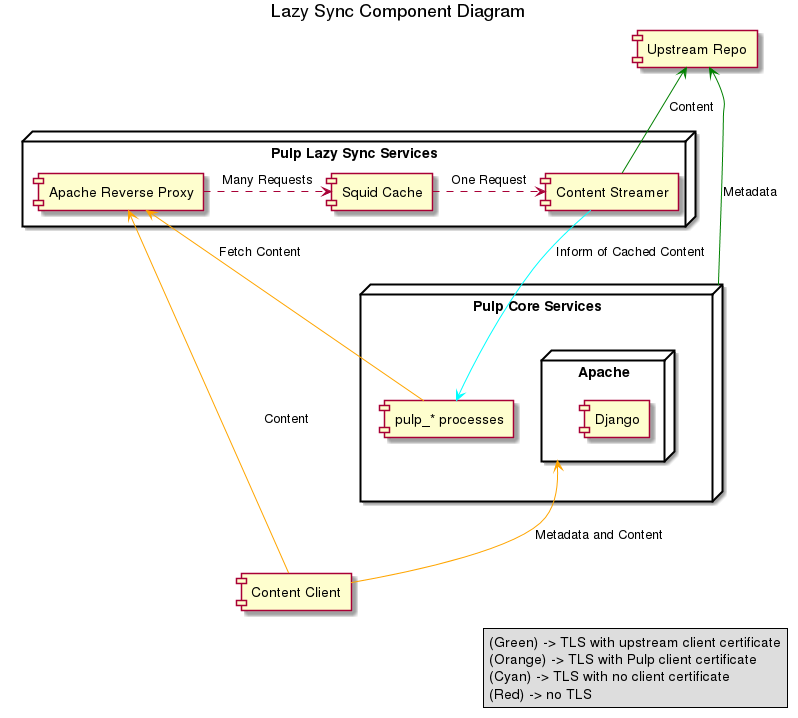
Deferred downloading relies on three services:
- A reverse proxy that terminates the TLS connection. In this guide Apache httpd is configured to act as the reverse proxy, but any reverse proxy that is capable of running a WSGI application should work. This service proxies the requests to the next service, a caching proxy server.
- A caching proxy server. In this guide Squid is used, but a simple Varnish configuration is also provided. This service de-duplicates client requests and caches content for Pulp to eventually save to permanent storage. It proxies requests on to the last service, the pulp_streamer
- The pulp_streamer is a streaming proxy service that translates the files in Pulp repositories to their locations in upstream repositories. This service interacts with Pulp’s core services to determine where the content is located and how to download it. It streams the content back to the client through Squid and Apache httpd as it is downloaded.
Clients request the content unit from Pulp’s core services. If the content has not been downloaded, Pulp redirects the client to the reverse proxy. Once the content has been downloaded, Pulp is informed that a new content unit has been downloaded and cached. At regular intervals, Pulp fetches the cached content and saves it so that when a client next requests it, Pulp can serve it directly.
Note
Although all three of these services must run together on the same host, they are not required to be on the same host(s) as the Pulp server. The one caveat to this is that the host must have the Pulp server configuration file, /etc/pulp/server.conf by default, and the RSA public key configured in that configuration file.
Installation¶
The packages necessary for deferred downloading can be installed with the following command:
$ sudo yum install httpd squid python-pulp-streamer
Ensure that the httpd, squid, and pulp_streamer services are running and enabled to start at boot.
Note
If you wish, you can replace httpd and squid with the reverse proxy and caching proxy of your choice. However, you will still need the python-pulp-streamer.
Configuration¶
If you have chosen to use the same host as the Pulp server, all the default settings in the lazy section of /etc/pulp/server.conf should work for you. If not, you will need to make some configuration adjustments so that Pulp redirects clients to the correct host. All configuration options are documented inline. Once the Pulp server is configured, the Apache httpd reverse proxy, Squid, and the Pulp streamer require configuration.
Reverse Proxy¶
A default configuration for Apache httpd is provided by the python-pulp-streamer package and is installed to /etc/httpd/conf.d/pulp_streamer.conf, but it is also reproduced below for reference:
# The first path in this `Alias` directive should match the `redirect_path` setting in
# /etc/pulp/server.conf
Alias /streamer /var/www/streamer
<Location /streamer/>
DirectoryIndex disabled
</Location>
<Directory /var/www/streamer>
# Enable URL signature checking
WSGIAccessScript /usr/share/pulp/wsgi/streamer_auth.wsgi
RewriteEngine on
# Remove the 'policy' and 'signature' query parameter if it is present in
# the request. Without this re-write, the caching proxy receives a different
# URL for each request and caching will be pointless.
#
# Each block checks for the existence of a key in the query string and, if
# present, rewrites the URL to remove the key and its value. It begins by
# attempting to find the string 'policy=' that is is directly after a '&'
# or ';', unless it starts the query string. Both '&' and ';' are valid
# separators in a query string. Next, it matches everything after the
# 'policy=' until it encounters another '&' or ';', or if the end of the
# string is reached. Finally, the string is rewritten with the 'policy='
# plus everything after it to the '&', ';', or end of string removed.
#
# For more information, see the mod_rewrite on syntax, see the mod_rewrite
# documentation.
RewriteCond %{QUERY_STRING} (.*)(?:^|&|;)policy=(?:[^(&|;)]*)((?:&|;|$).*)
RewriteCond %1%2 (^|&|;)([^(&|;)].*|$)
RewriteRule ^(.*)$ $1?%2 [DPI]
RewriteCond %{QUERY_STRING} (.*)(?:^|&|;)signature=(?:[^(&|;)]*)((?:&|;|$).*)
RewriteCond %1%2 (^|&|;)([^(&|;)].*|$)
RewriteRule ^(.*)$ $1?%2 [DPI]
# Proxy all requests on to the Squid server. If you are using a different caching
# proxy server, either modify the port it listens on, or change the port here.
# For example, Varnish listens on TCP port 6081 by default so this rewrite rule
# would change to: RewriteRule (.*) http://127.0.0.1:6081/$1 [P]
RewriteRule (.*) http://127.0.0.1:3128/$1 [P]
</Directory>
# By default, Apache doesn't pool reverse proxy TCP connections unless you create a worker
# using the `Proxy` directive. If you are not using Apache to reverse proxy, you probably
# don't need any equivalent to this configuration. You will also need to change the port
# number used here if you are not using Squid, or if Squid is not listening on its default
# port.
<Proxy http://127.0.0.1:3128>
ProxySet connectiontimeout=60
</Proxy>
Caching Proxy¶
There are many caching proxies and the only requirement Pulp has is that they should support (and enable) pre-fetching the entire requested file when they receive a request with the HTTP Range header.
Squid¶
Squid requires significantly more configuration which is up to the user. To configure squid, edit /etc/squid/squid.conf. The following is a basic configuration with inline documentation that should work for Squid 3.2 or greater. Since Red Hat Enterprise Linux 6 and CentOS 6 ships with Squid 3.1, users of those platforms will need to uncomment a few configuration options:
# Recommended minimum configuration. It is important to note that order
# matters in Squid's configuration; the configuration is applied top to bottom.
# Listen on port 3128 in Accelerator (caching) mode. Squid 3.1 users should use
# the commented out version of this statement and update the default site if the
# Pulp streamer isn't listening on 127.0.0.1:8751.
# http_port 3128 accel defaultsite=127.0.0.1:8751
http_port 3128 accel
# Squid 3.1 doesn't define these Access Control Lists by default. RHEL/CentOS 6
# users should uncomment the following acl definitions.
# acl manager proto cache_object
# acl localhost src 127.0.0.1/32 ::1
# acl to_localhost dst 127.0.0.0/8 0.0.0.0/32 ::1
# Only accept connections from the local host. If the Apache httpd reverse
# proxy is running on a different host, adjust this accordingly.
http_access allow localhost
# Allow requests with a destination that matches the port squid
# listens on, and deny everything else. This is okay because we
# only handle requests from the Apache httpd reverse proxy.
acl Safe_ports port 3128
http_access deny !Safe_ports
# Only allow cachemgr access from localhost
http_access allow localhost manager
http_access deny manager
# We strongly recommend the following be uncommented to protect innocent
# web applications running on the proxy server who think the only
# one who can access services on "localhost" is a local user
http_access deny to_localhost
# And finally deny all other access to this proxy
http_access deny all
# Forward requests to the Pulp Streamer. Note that the port configured here
# must match the port the Pulp Streamer is listening on. The format for
# entries is: cache_peer hostname type http-port icp-port [options]
#
# The following options are set:
# * no-digest: Disable request of cache digests, as the Pulp Streamer does not
# provide one
# * no-query: Disable ICP queries to the Pulp Streamer.
# * originserver: Causes the Pulp Streamer to be contacted as the origin server.
# * name: Unique name for the peer. Used to reference the peer in other directives.
cache_peer 127.0.0.1 parent 8751 0 no-digest no-query originserver name=PulpStreamer
# Allow all queries to be forwarded to the Pulp Streamer.
cache_peer_access PulpStreamer allow all
# Ensure all requests are allowed to be cached.
cache allow all
# Set the debugging level. The format is 'section,level'.
# Valid levels are 1 to 9, with 9 being the most verbose.
debug_options ALL,1
# Set the minimum object size to 0 kB so all content is cached.
minimum_object_size 0 kB
# Set the maximum object size that can be cached. Default is to support DVD-sized
# objects so that ISOs are cached.
maximum_object_size 5 GB
# Sets an upper limit on how far (number of bytes) into the file
# a Range request may be to cause Squid to prefetch the whole file.
# If beyond this limit, Squid forwards the Range request as it is and
# the result is NOT cached.
#
# A value of 'none' causes Squid to always prefetch the entire file.
# This is desirable in all cases for Pulp and is required to Kickstart
# from repositories using deferred download policies.
range_offset_limit none
# Objects larger than this size will not be kept in the memory cache. This should
# be set low enough to avoid large objects taking up all the memory cache, but
# high enough to avoid repeatedly reading hot objects from disk.
maximum_object_size_in_memory 100 MB
# Set the location and size of the disk cache. Format is:
# cache_dir type Directory-Name Fs-specific-data [options]
#
# * type specifies the type of storage system to use.
# * Directory-Name is the top-level directory where cache swap files will be stored.
# Squid will not create this directory so it must exist and be writable by the
# Squid process.
# * Fs-specific-config varies by storage system type. For 'aufs' and 'ufs' the data
# is in the format: Mbytes L1 L2.
# - Mbytes is the number of megabytes to use in this cache directory. Note that
# that this should never exceed 80% of the storage space in that directory.
# - L1 is the number of first-level subdirectories which are created under the
# root cache directory (Directory-Name).
# - L2 is the number of second-level subdirectories which will be created under
# each L1 subdirectory.
#
# Be aware that this directive must NOT precede the 'workers' configuration option
# and should use configuration macros or conditionals to give each squid worker that
# requires a disk cache a dedicated cache directory.
#
# 'aufs' uses layered directories to store files, utilizing POSIX-threads to avoid
# blocking the main Squid process on disk-I/O. This was formerly known in Squid
# as async-io.
#
# 'ufs' is simple to set up and available in all recent version of Squid,
# but should not be used in a production environment. 'ufs' does not make use of
# threads for I/O, so it blocks when reading from or writing to the cache.
#
# 'rock' uses a database-style storage. All cached entries are stored in a
# 'database' file, using fixed-size slots. A single entry occupies one or more
# slots. 'rock' performs best with small files, whereas 'aufs' works best with
# larger files. A combination of the two can be used in advanced deployments.
cache_dir aufs /var/spool/squid 10000 16 256
# Leave coredumps in the first cache dir
coredump_dir /var/spool/squid
#
# Define how long objects without a explicit expiry time are considered fresh.
# All responses from the Pulp Streamer should enclude a max-age, but this is
# a way to ensure all objects become stale eventually.
#
# Add any of your own refresh_pattern entries above these.
#
refresh_pattern ^ftp: 1440 20% 10080
refresh_pattern ^gopher: 1440 0% 1440
refresh_pattern -i (/cgi-bin/|\?) 0 0% 0
refresh_pattern . 0 20% 4320
For more information about a configuration option, please consult the Squid documentation.
Varnish¶
If you choose to use Varnish instead of Squid, there are two configuration files to look at. The first is /etc/varnish/default.vcl, where you will need to change the port Varnish proxies to:
# Default backend definition. Set this to point to the Pulp streamer, which is port 8751
# by default.
backend default {
.host = "127.0.0.1";
.port = "8751";
}
The second is /etc/varnish/varnish.params where, among other things, the cache size and location is set.
Pulp Streamer¶
Finally, the Pulp streamer has several configuration options available in its configuration file, found by default in /etc/pulp/streamer.conf.
Pulp-admin Usage¶
Once deferred downloading components have been configured, you can create repositories that use deferred download policies:
$ pulp-admin rpm repo create --help
Download Policy
--download-policy - content downloading policy (immediate | background |
on_demand)
$ pulp-admin rpm repo create --repo-id=zoo --download-policy=on_demand \
--feed=https://repos.fedorapeople.org/repos/pulp/pulp/demo_repos/zoo/
$ pulp-admin rpm repo sync run --repo-id=zoo
Both on-demand and background download policies allow you to manipulate the repository after a sync is complete.
On-demand Download Repositories¶
This will configure the repository to skip downloading files during syncs. Once a sync and publish has completed, the repository is ready to serve content to clients even though no content has been downloaded yet. When a client requests a file, such as an RPM, Pulp will perform the download from the upstream zoo repository and serve that file to the client. It will then save the file for any other clients that request that file.
Background Download Repositories¶
This will configure the repository to skip downloading files during a sync, but once a sync has been completed it will dispatch a task to download all the files. This is equivalent to running:
$ pulp-admin rpm repo create --repo-id=zoo --download-policy=on_demand \
--feed=https://repos.fedorapeople.org/repos/pulp/pulp/demo_repos/zoo/
$ pulp-admin rpm repo sync run --repo-id=zoo
$ pulp-admin repo download --repo-id=zoo
Deferred Downloading with Alternate Content Sources¶
Alternate Content Sources can be used in conjunction with deferred downloading.
Note
If the alternate content source is configured to have a file:// base URL, that URL must be valid for the host running pulp_streamer. If pulp_streamer is running on a different host than the core Pulp services, the pulp_streamer host should have access to both the Content Sources configuration directory and the file:// URL.
Re-Using Files On Disk When DB Is Lost¶
Given a situation where the database has been lost, but the files within /var/lib/pulp/content/ are still present, it is possible to re-use those files when creating new repositories by using Pulp’s deferred download functionality. For each repository that needs to be recreated, follow the steps below.
Note
This strategy only works for plugins that support the deferred download functionality.
Create the new repository with a download policy of on_demand.
Sync the new repository. This will populate the database with knowledge of each remote piece of content without actually downloading the files.
Run the download_repo task with the verify_all_units option set to True. This will check the filesystem for existing files and verify their integrity, only downloading a file from the remote source if it is not found on disk. From the command line:
pulp-admin repo download --repo-id=myrepo --verify-all
Change the download policy of the repository to whichever policy you want to use long-term.
Note
There is a known issue that will prevent the units from having their downloaded attribute from being set to True. That may not matter unless you depend on that attribute being correct.
Troubleshooting¶
When troubleshooting, it is best to have a repository that has been configured with the on_demand deferred download policies. This repository should be synced and published before you begin. To determine the correct URL for a package in your test repository, you can inspect the filesystem:
$ sudo tree /var/lib/pulp/published/yum/https/
/var/lib/pulp/published/yum/https
└── repos
├── listing
└── zoo -> /var/lib/pulp/published/yum/master/yum_distributor/zoo/1455306817.77
├── bear-4.1-1.noarch.rpm -> /var/lib/pulp/content/units/rpm/76/78177c241777af22235092f21c3932dd4f0664e1624e5a2c77a201ec70f930/bear-4.1-1.noarch.rpm
├── penguin-0.9.1-1.noarch.rpm -> /var/lib/pulp/content/units/rpm/bb/a187163c14f7e124009157c58e615cccf9eda81a8c09949bf4de2398a53bbe/penguin-0.9.1-1.noarch.rpm
├── pike-2.2-1.noarch.rpm -> /var/lib/pulp/content/units/rpm/41/b650e4f1780e67eeb83357d552cc0aacde317f7305b610cbd2ac01b3c6ab4b/pike-2.2-1.noarch.rpm
├── repodata
│ ├── 06344f163d806c2e2ef2659d9b4901489001fa86f11fbf2296f5f0aa0bc4aa08-updateinfo.xml.gz
│ ├── 1a186f16ca6545f8f5f08c93faab0ec6943b9e549be58c1d5512ac6f06244f7f-other.xml.gz
│ ├── 1f3a7be8dc71f12871909ffc8d3aa3c28d13363001f07be0eb3bf268ee1fa9b8-filelists.xml.gz
│ ├── 9ab1052ece4a7818d385abca3a96e053bb6396a4380ea00df20aeb420c0ae3c7-comps.xml
│ ├── cce58258de4672edc22a3eefa3bc177a8fa90d716f609c82a33454d1c07abae0-primary.xml.gz
│ └── repomd.xml
└── zebra-0.1-2.noarch.rpm -> /var/lib/pulp/content/units/rpm/38/0ef86bf1d303febdd2b990fe971611ee49ab9b267077568f23d81babe96dfc/zebra-0.1-2.noarch.rpm
Assuming you have not modified the provided Apache httpd configurations, the URL for /var/lib/pulp/published/yum/https/repos/zoo/duck-0.6-1.noarch.rpm is, assuming the fully-qualified domain name of Pulp is dev.example.com, https://dev.example.com/pulp/repos/zoo/duck-0.6-1.noarch.rpm.
Pulp is not redirecting¶
To ensure Pulp is redirecting to the reverse proxy server, cURL the URL you obtained above. If something is wrong, you may see something like:
$ curl -O -k -v "https://dev.example.com/pulp/repos/zoo/duck-0.6-1.noarch.rpm"
* Connected to dev.example.com (127.0.0.1) port 443 (#0)
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* skipping SSL peer certificate verification
* ALPN, server accepted to use http/1.1
* SSL connection using TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA
* Server certificate:
* subject: E=root@dev,CN=dev,OU=SomeOrganizationalUnit,O=SomeOrganization,L=SomeCity,ST=SomeState,C=--
* start date: Feb 01 14:00:37 2016 GMT
* expire date: Jan 31 14:00:37 2017 GMT
* common name: dev
* issuer: E=root@dev,CN=dev,OU=SomeOrganizationalUnit,O=SomeOrganization,L=SomeCity,ST=SomeState,C=--
> GET /pulp/repos/zoo/duck-0.6-1.noarch.rpm HTTP/1.1
> Host: dev.example.com
> User-Agent: curl/7.43.0
> Accept: */*
>
* skipping SSL peer certificate verification
* NSS: client certificate not found (nickname not specified)
* ALPN, server accepted to use http/1.1
* skipping SSL peer certificate verification
* ALPN, server accepted to use http/1.1
< HTTP/1.1 404 NOT FOUND
< Date: Tue, 02 Feb 2016 15:48:07 GMT
< Server: Apache/2.4.18 (Fedora) OpenSSL/1.0.2f-fips mod_wsgi/4.4.8 Python/2.7.10
< Content-Length: 54
< Content-Type: text/html; charset=utf-8
- Note the 404 NOT FOUND response. This can occur for a few reasons:
- /etc/httpd/conf.d/pulp_content.conf is not present or is failing to load and run the WSGI application found at /usr/share/pulp/wsgi/content.wsgi
- The rewrite rules provided by each plugin are not present. For example, /etc/httpd/conf.d/pulp_rpm.conf contains rewrite rules for RPM content.
- The URL you used does not correspond to a file in the repository.
Ensure both these configuration files are present and that the rewrite is occurring. To check the rewrite is occurring, consult the documentation for the version of mod_rewrite you have installed. The documentation for the most recent release can be found here. Please note that changes occurred to the logging directives between the 2.2 and 2.4 releases of Apache httpd.