Deferred Download Design¶
This section discusses the details of the the deferred downloading services and how they integrate with Pulp’s core services.
Component Overview¶
Three additional services were necessary in order to support deferred downloading. In addition to these new services, several changes were made to the platform.
Pulp Content WSGI Application¶
The Pulp Content WSGI application was created because Apache does not provide a good way to redirect the client appropriately when the content is missing. When a broken link is encountered by Apache, it returns a HTTP 403 Forbidden, and while it is possible to add a custom ErrorDocument directive for HTTP 403, Pulp uses HTTP 403 in other cases. The WSGI application determines whether or not the client has access, and it determines whether the requested file is part of a repository or not. This change is a part of the platform.
Apache Reverse Proxy¶
Although it is possible to use the same instance of Apache for both Pulp and the deferred download services, it is not required. Therefore, it is best to think of this as a new service. The Apache reverse proxy serves as a way to terminate TLS connections with clients. This is required because Squid cannot cache encrypted content. In addition to terminating the TLS connection, the Apache reverse proxy also makes use of a WSGI access script, which validates that the URL has been cryptographically signed by Pulp and has not expired.
Squid Cache¶
Technically, Squid is not required for deferred downloading to work, but it provides two very important performance enhancements that are required for any production deployment.
The first is that Squid de-duplicates client requests. This is helpful since it is not unlikely that many clients request the same content at the same time. Rather than downloading the content many times concurrently, Squid makes a single request on behalf of the clients.
The second is that Squid caches the files it downloads, so that the next time a client requests them, Squid services the request from its cache. This is important because Pulp downloads all cached content from Squid at regular intervals and it would be wasteful to download the content from the Internet twice. It is also important because until Pulp downloads the content from the cache, Squid will receive all requests for the content from clients.
Pulp Streamer¶
The Pulp Streamer is the component that interfaces with Pulp to determine where the requested content can be found. It does this by consulting a collection in the database, which maps files to URLs, download settings, and, if necessary, entitlement certificates. Rather than downloading the entire file and returning it to Squid, it returns the downloaded bits to Squid as it receives them. This ensures the client does not time out the connection, since Squid will in turn stream the content back to Apache, which will stream back to the client.
Sequence Diagram¶
The following sequence diagram provides a more detailed view of how the services interact than the component diagram above:
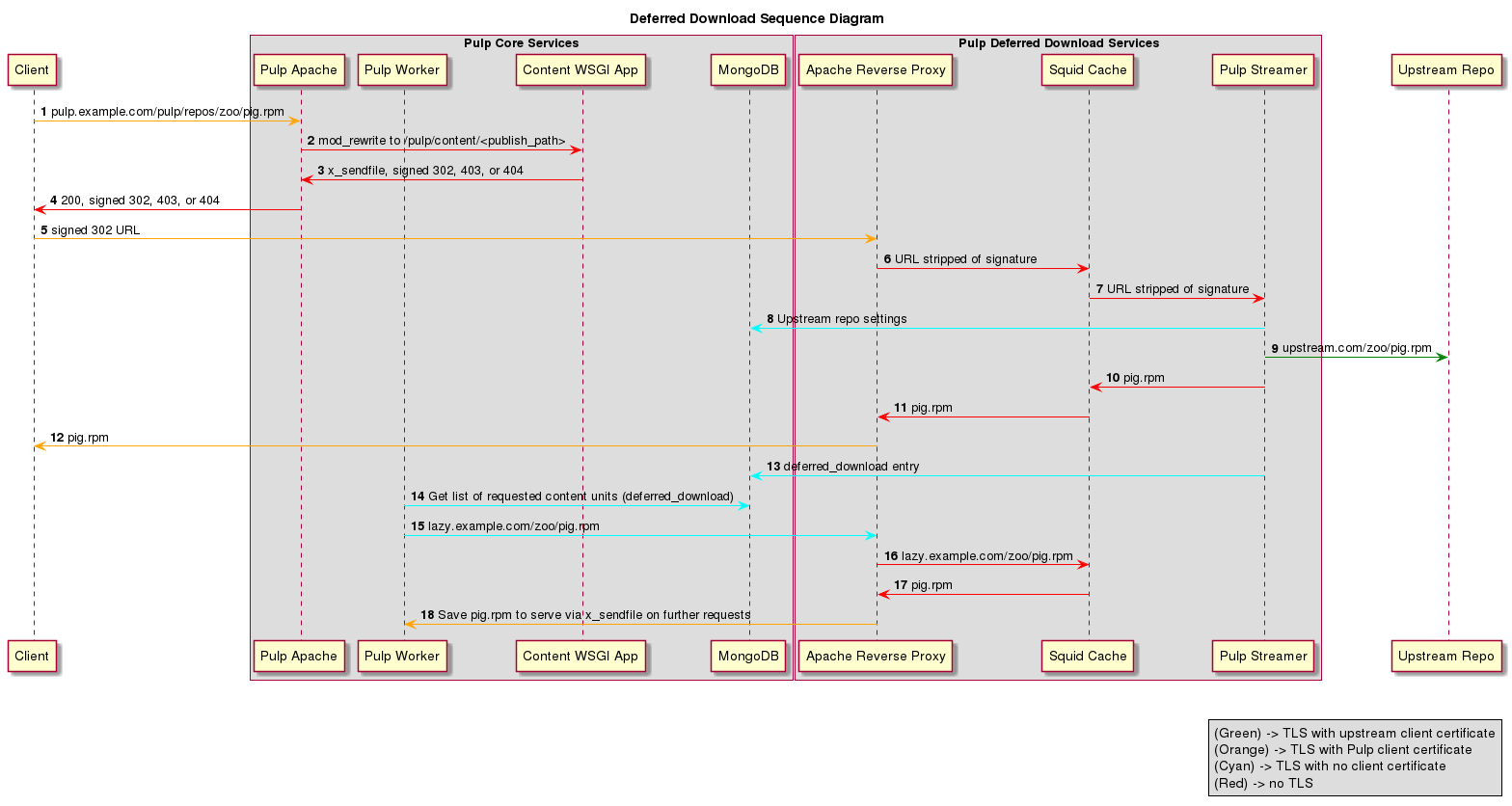
- The client requests a content unit from Pulp, just as it would without lazy content loading. This includes potentially offering a client certificate for content entitlement.
- The requested URL is re-written using Apache’s mod_rewrite to a location in /pulp/content/. Each Pulp plugin provides one or more re-write rules as part of its configuration.
- A WSGI application is configured to handle all requests to /pulp/content/. When a request is made, the application confirms the client is entitled to the content. If the client is not entitled, the WSGI application returns a HTTP 403 Forbidden to the client. If the client is entitled, the WSGI application checks to see if the file exists in the repository by looking for the symbolic link in the published repository. If it is not present, a HTTP 404 is returned. If it is present, the link is followed. If the location the link points to exists, the WSGI application uses mod_xsendfile so that Apache serves the file. If the location the link points to does not exist, the WSGI application creates a signed URL and returns that.
- Apache serves the appropriate response to the client. The following steps only occur if the HTTP 302 Redirect is returned.
- The client follows the redirect URL. This request is handled by the Apache reverse proxy. It is first passed through a WSGIAccessScript in order to validate the URL signature. Once validated, Apache uses mod_rewrite to strip the signature from the URL. This occurs so that the URL does not differ for the same file so that Squid can retrieve the cached content for subsequent requests.
- Apache acts as a reverse proxy and makes a plaintext request to Squid on behalf of the client.
- Squid performs a cache lookup on the requested content. If it is available, it is served to Apache, which in turn serves it to the client. If the cache lookup results in a miss, Squid makes a request to the Pulp Streamer.
- The Pulp Streamer determines the correct upstream URL and entitlement certificates by looking the requested content up in the content catalog in MongoDB.
- The Pulp Streamer makes a request to the upstream repository, using any entitlement certificates necessary.
- The Pulp Streamer forwards the results of the request to Squid as it receives them.
- Squid streams content received from the Pulp Streamer to Apache and caches the content for future requests.
- The Apache reverse proxy streams the content back to the client.
- The Pulp Streamer adds an entry to the DeferredDownload database collection to indicate to the Pulp server that a content unit has been cached and is ready for retrieval for permanent storage.
- At regular intervals a task is dispatched by Pulp to download all content specified in the DeferredDownload collection. This task retrieves the entries made by the Pulp Streamer.
- For each deferred download entry, the task determines all the files in the content unit associated with the file that triggered the deferred download entry and requests them from the Apache reverse proxy using a URL it signs for itself.
- Apache forwards the request to Squid.
- Squid returns the files it has cached, or retrieves them from the streamer if they are not found in the cache.
- Apache returns the requested content to the task, which is saved so that Pulp itself can return the content using mod_xsendfile to clients that request it in the future. The task marks the content unit as downloaded when all its files are saved locally.
Known Flaws¶
This design, like all the other proposed designs, has a few known efficiency problems. There are several cases, outlined below, where content is downloaded multiple times by Pulp from the Squid proxy. Although this does not access an external network, it is still considered undesirable since it consumes disk I/O unnecessarily.
Multiple Downloads¶
A content unit could be downloaded multiple times if a client requests a file in that unit and then a download_repo task for a repository that contains that unit and the celerybeat deferred_downloads task run at the same time, and they happen to process the that content unit at the same time.
A content unit could be downloaded multiple times if the deferred_downloads task is set to run often enough that a new task is dispatched before the old one is finished. If those tasks select the same units at the same time, they could download the same content twice. This is a fairly narrow window as each task should be reading and then removing the document from MongoDB, but it is by no means impossible.
A content unit could be downloaded multiple times if a client is actively requesting content from a multi-file ContentUnit. This occurs if the deferred_downloads task removes an entry to process, and then the client asks for a new file (that isn’t cached in Squid). The Streamer will be able to add another entry for that ContentUnit there is no longer an entry for that (unit_id, unit_type_id).
Mitigation: Have both download_repo and deferred_downloads regularly check the ContentUnit.downloaded flag on the units it is processing. This way it can detect if another task has already downloaded the unit and quit.
Lost Downloads¶
Since the deferred_downloads task removes entries from the collection, it is possible for a lazy=passive download to be lost by Pulp if the worker is killed before it finishes the download, but after it has removed the database record(s).
Mitigation: Have the deferred_downloads task remove relatively few entries at a time. This is a matter of balancing the performance of parallelizing downloads versus losing entries and having to wait for the Squid cache to expire and cause the Streamer to add the entry back to the deferred_downloads collection. A user can also dispatch a download_repo task if they want these lost units to be downloaded by Pulp.